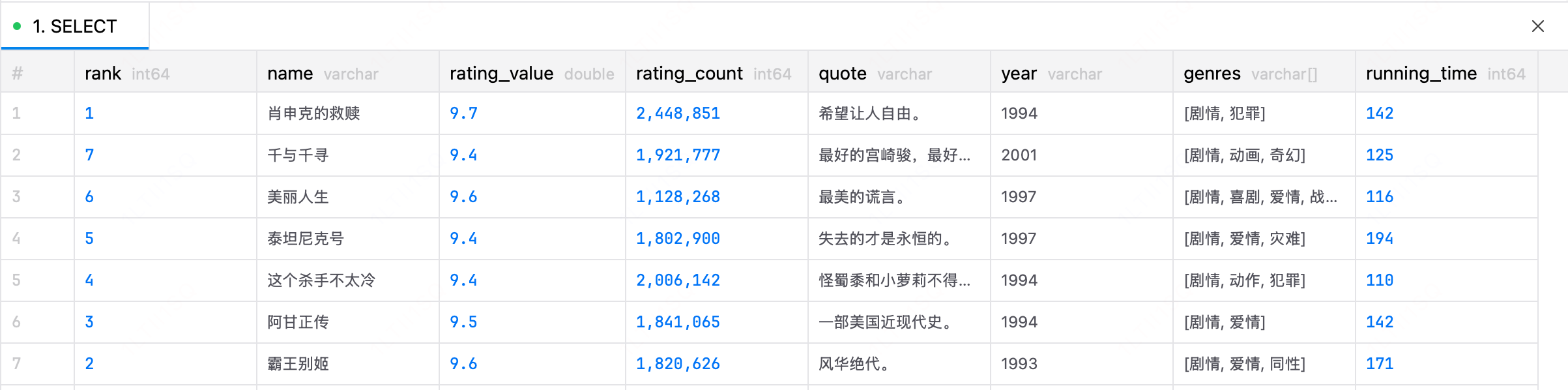
数据表结构
电影数据表的字段构成如下:
常规函数
示例:查询 1990 年代且排名在 11-15 的电影,返回排名、电影名和年份的组合文本,以及所属年代。
SELECT
rank,
concat_ws('|', name, year) AS name_and_year,
concat(SUBSTR(year, 1, 3), '0') AS decade
FROM
top_movies
WHERE
rank BETWEEN 11 AND 15
AND concat(SUBSTR(year, 1, 3), '0') = '1990';
concat_ws:用指定分隔符连接字符串BETWEEN...AND...:范围查询(包含边界值)SUBSTR:从字符串中按索引提取子串,索引从 1 开始
日期函数
常用的日期函数包括:
to_date:将时间字符串转换为日期格式datediff:计算两个日期之间的天数差date_sub/date_add:对日期进行加减指定天数的操作
逻辑函数
示例:筛选 1993 年的电影,根据评分值分别生成对应的评价文本。
SELECT
name,
rating_value,
CASE
WHEN rating_value >= 9.0 THEN '9 分电影'
WHEN rating_value >= 8.5 THEN '8.5 分电影'
ELSE '8 分'
END AS rating
FROM
top_movies
WHERE
year = 1993;
CASE...WHEN...THEN...ELSE...END:根据条件输出不同的返回值IF:简单的逻辑判断函数
聚合函数
示例:按年度聚合数据,统计各年度电影的评分最高值、最低值、平均值、数量以及所有电影名称列表。查询结果仅包含电影数量不少于 10 部的年份。
SELECT
year,
max(rating_value) AS max_rating,
min(rating_value) AS min_rating,
avg(rating_value) AS avg_rating,
count(name) AS movies_count,
group_concat(name) as movies
FROM
top_movies
GROUP BY
year
having
count(name) >= 10
ORDER BY
year;
联合查询 (JOIN)
示例:进行自表联合查询,查找年份和时长相同的电影对。
SELECT
concat_ws('-', t1.rank, t1.name, t1.year, t1.running_time) as rank_name_year_rating,
concat_ws('-', t2.rank, t2.name, t2.year, t2.running_time) as rank_name_year_rating
FROM
top_movies AS t1
JOIN top_movies AS t2 ON t1.year = t2.year
AND t1.running_time = t2.running_time
AND t1.rank != t2.rank
order by t1.rank;